ผมเชื่อว่ามนุษย์ทุกคนล้วนรู้จักการเปรียบเทียบครับ จริง ๆ แล้วมนุษย์เรานั้นเปรียบเทียบได้เก่งกว่า computer ซะอีก แต่มันก็ช่วยไม่ได้อ่ะครับ เพราะในเมื่อมนุษย์เราสร้าง computer ขึ้นมาเพื่อช่วยงานเราแล้ว ไอ้ครั้นจะให้มันมีเพียงกลไกในการคำนวณทางคณิตศาสตร์เพียงอย่างเดียว ก็คงเป็นไปไม่ได้อ่ะ เราก็เลยต้องบรรจุกลไกการเปรียบเทียบให้มันด้วย
เวลาไอ้เจ้า computer มันเปรียบเทียบ มันก็เปรียบเทียบได้พื้น ๆ ใช่แมะ? เช่น น้อยกว่า, มากกว่า, เท่ากับ, ไม่เท่ากับ และเงื่อนไขอื่นอีกนิดหน่อย แล้วมันก็ให้ผลลัพท์กับเรามาเป็นค่า “จริง”, “เท็จ” หรือ “ใช่”, “ไม่ใช่” ซึ่งปรกติแล้ว digital computer มันก็คงจะแทนค่าอะไรไม่ได้มากไปกว่าการให้เลข 0 เพื่อแทนค่าเท็จหรือค่าไม่ใช่ และการให้เลข 1 เพื่อแทนค่าจริงหรือค่าใช่ เป็นต้น
ซึ่งสรุปได้สั้น ๆ ว่า digital computer ถ้าเปรียบเป็นคนแล้ว ถือว่าเป็นคนเถรตรงมากเลย แบบว่าเป๊ะ ๆ มีแค่จริงกับไม่จริงเท่านั้น เหมือนตอบคำถามในศาลครับ ที่เวลาทนายมาถาม เราก็ตอบได้แค่เนี้ย “ใช่” หรือ “ไม่ใช่ อ่ะ
ทีนี้ภายหลังการเกิดขึ้นของ digital computer ราว 20 กว่าปี ก็เลยมีนักวิทยาศาสตร์ทาง computer คิดกันขึ้นมาได้ว่า computer มันน่าจะให้น้ำหนักกับความ “ใช่”, “ไม่ใช่” หรือ ความ “จริง”, ความ “ไม่จริง” ด้วยดิ ซึ่งความคิดที่ได้ก็ตกผลึกออกมาว่า ผลลัพท์จากการเปรียบเทียบของ computer ไม่ควรจะมีค่าแค่ 0 หรือ 1 แต่มันควรมีค่าเป็นเลขจำนวนจริงซึ่งมีค่าตั้งแต่ 0 ถึง 1 ต่างหาก
ซึ่งนั่นก็คือที่มาของ Fuzzy Logic ศาสตร์ซึ่งมีการให้น้ำหนักกับค่าความจริงและความเท็จ แบบนี้ผมก็ว่าดีนะ เพราะแค่มันให้ผลลัพท์กับผมมาเป็นเกือบใช่ ซึ่งอาจจะมีค่า 0.854321 ผมก็ o.k ถือว่าเข้าเงื่อนไขแห่งความใช่ได้แล้ว แต่ก็ไม่ใช่ว่าค่า 0.854321 จะถือเป็นค่าที่เข้าเงื่อนไขทุกครั้งไป เพราะในเงื่อนไขถัด ๆ ไป ผมอาจจะยอมให้ค่า 0.8421577 เป็นค่าเกือบใช่ที่ผมยอมรับได้ หรือไม่ก็อาจจะโหดหน่อย ต้องได้ซัก 0.9999213 ถึงจะเข้าข่ายเป็นค่าเกือบใช่ที่ยอมรับได้เป็นต้น ซึ่งเหล่านี้ขึ้นอยู่กับ algorithm ของ fuzzy logic ที่เรากำหนดขึ้นมา แบบว่าตัวแปรมากระทบกับมันเยอะ ดังนั้นทั้งผลลัพท์และเงื่อนไขก็ต้องยืดหยุ่นกันหน่อย
แต่ถึงแม้ในทาง computer จะมีทั้งการเปรียบเทียบปรกติ และการเปรียบเทียบแบบให้น้ำหนักโดยใช้ Fuzzy Logic แต่มันก็ยังไม่พอหรอก เคยสังเกตุมั้ยครับว่าการเปรียบเทียบในทางคณิตศาสตร์จะมีสัญลักษณ์นึงที่เรียกว่า “ความคล้าย” เขียนงี้ครับ “~” เช่นถ้าตัวแปร A คล้ายกับตัวแปร B ก็เขียนได้เป็น A ~ B เป็นต้น
ในทางคณิตศาสตร์มีความคล้าย แต่ในทาง computer มันมีที่ไหนกันเล่า? ไอ้เจ้า computer มันเถรตรงจะตายไป แค่จะมี Fuzzy Logic ก็ลำบากพอดูแล้ว
ทีนี้ความคล้ายมันจำเป็นแค่ไหนในทาง computer??? เอ้อ เผอิญมันจำเป็นอ่ะครับ เพราะทฤษฎีทาง computer ชั้นสูงจะไม่สามารถแก้ปัญหาได้เลย ถ้าเราไม่ยอมรับความคล้ายให้ไปมีบทบาทในทฤษฎีเหล่านั้น
 ทุกวันนี้เรามีความต้องการให้ computer ทำหลาย ๆ อย่างที่ยาก ๆ เน้อะ เช่น เราหวังจะให้มันจำได้ว่าเสียงพูดเนี้ยเป็นเสียงของใคร (Voice Recognition), หวังจะให้มันรู้ว่าเราพูดคำพูดอะไร (Speech Recognition), อยากให้มันอ่านลายนิ้วมือแล้วรู้ว่าเป็นลายนิ้วมือของใคร, อยากให้มันจำหน้าของคนได้, อยากให้มันอ่านพวก barcode ได้, อยากจะให้มันอ่านรูปภาพซึ่งมีตัวหนังสือเยอะ ๆ แล้วให้มันแปลงเป็นข้อความใน computer, อยากเขียนยึกยือบนกระดาษแล้วให้มันรู้ว่าเขียนว่าอะไร ฯลฯ อีกจิปาถะ
ทุกวันนี้เรามีความต้องการให้ computer ทำหลาย ๆ อย่างที่ยาก ๆ เน้อะ เช่น เราหวังจะให้มันจำได้ว่าเสียงพูดเนี้ยเป็นเสียงของใคร (Voice Recognition), หวังจะให้มันรู้ว่าเราพูดคำพูดอะไร (Speech Recognition), อยากให้มันอ่านลายนิ้วมือแล้วรู้ว่าเป็นลายนิ้วมือของใคร, อยากให้มันจำหน้าของคนได้, อยากให้มันอ่านพวก barcode ได้, อยากจะให้มันอ่านรูปภาพซึ่งมีตัวหนังสือเยอะ ๆ แล้วให้มันแปลงเป็นข้อความใน computer, อยากเขียนยึกยือบนกระดาษแล้วให้มันรู้ว่าเขียนว่าอะไร ฯลฯ อีกจิปาถะ
แล้วก็คงเป็นเพราะความขยันของมนุษย์ จึงทำให้มีนักวิทยาศาสตร์ทาง computer หลาย ๆ กลุ่ม ช่วย ๆ กันคิดทฤษฎีหลาย ๆ อย่างขึ้นมา ซึ่งผลลัพท์ของมันก็คือการทำ Pattern Recognition นั่นเอง
ศาสตร์ทาง Pattern Recognition จึงมีความหมายถึง การนำข้อมูลหนึ่งชุด ไปเปรียบเทียบกับข้อมูลหลายสิบ, ร้อย, พัน, หมื่น, แสน, ล้านชุด แล้วหาดูว่าข้อมูลหนึ่งชุดที่ว่า มีความคล้ายคลึงกับข้อมูลชุดใดในจำนวนชุดข้อมูลอันมากมายมหาศาลเหล่านั้น เหมือนกับเรามีรูปถ่ายของใครคนนึงเน้อะซึ่งถ่ายเมื่อสองปีก่อน แล้วเราต้องออกตามหาคน ๆ นั้น ซึ่งตอนนี้หน้าอาจจะแก่ขึ้นนิดหน่อย หรือไว้หนวดไว้เครา หรือมีรอยแผลเป็นขึ้นมาบนใบหน้า แบบนั้นเลยอ่ะ
การทำ Pattern Recognition มีทฤษฎีหลาย ๆ ตัวสนับสนุนอยู่ เจ้า Pattern Recognition มันก็เป็นแค่คำกลาง ๆ ที่อธิบายความหมายของย่อหน้าข้างบน จุดที่น่าสนใจคงจะเป็นทฤษฎีซึ่งประยุกต์ใช้กับ Pattern Recognition มากกว่า
เท่าที่ผมรู้และเคยมีประสบการณ์มา ผมรู้มาว่านักวิทยาศาสตร์ได้ใช้ทฤษฎีทาง computer science และ statistical มาช่วยในการทำ Pattern Recognition ไม่ว่าจะเป็น Neural Network, Hidden Markov Model, Vector Quantization, Linear Predictive Coding Model เป็นต้น ทฤษฎีพวกนี้ก็แยก ๆ กันไปศึกษาอ่ะครับ บ้างก็เอามารวม ๆ กันใช้ทำ Pattern Recognition บ้าง แล้วแต่สถานการณ์จะเอื้ออำนวย
ผู้ร่วมงานผมเพิ่งจะจบปริญญาโททางด้าน multi-media ครับ จบมาได้วิทยาศาสตร์มหาบัณฑิต เขาทำวิทยานิพนธ์เรื่องเกี่ยวกับ Image Processing คือแบบว่าเขาจะถ่ายภาพภาษามือ ซึ่งมันจะมีประโยชน์กับคนใบ้หรือคนหูหนวกอ่ะครับ ถ่ายแล้วเก็บเข้าฐานข้อมูลด้วยทฤษฎี Neural Network แบบว่าถ่ายไว้ครบทุกคำของภาษาใบ้เลยมั้ง จากนั้นก็ทำ Pattern Recognition นั่นแหล่ะครับ โดยการถ่ายภาพภาษามือ แล้วเอาไปเปรียบเทียบกับภาษามือซึ่งมีเป็นร้อย ๆ ในฐานข้อมูล แล้วแสดงผลออกมาเป็นคำพูด เช่น ถ้าเปรียบเทียบแล้วพบว่าภาษามือนั้นหมายถึงการกิน เขาก็จะแสดงผลออกมาที่หน้าจอเป็นตัวอักษรโต ๆ ว่า “กิน” เป็นต้น
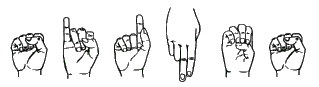
เอ แต่เท่าที่ดูมันไม่ใช่แค่ช่วยคนใบ้หรือหูหนวกเน้อะ เพราะถ้าทำเสร็จแล้วมันช่วยพวกเราได้ด้วย ช่วยพวกเราให้เข้าใจได้ว่าคนใบ้หรือคนหูหนวกต้องการสื่อสารอะไรกับเรา โดยการจับภาพภาษามือ แล้วมี sub-title เป็นข้อความให้เราอ่านเพื่อทำความเข้าใจ ดี ๆ
ประเด็นที่ผมถามเพื่อนร่วมงานก็คือ Neural Network ที่เขาทำ ให้ความแม่นยำที่กี่ percent ซึ่งเขาตอบกลับมาว่า “ได้แค่ 85% เองพี่ไท้”
เป็นประเด็นที่โป๊ะเช้ะมากเลย เพราะจากการค้นคว้าของผมหลายปี ผมพบว่าไม่ว่าจะเป็นปริญญานิพนธ์หรือวิทยานิพนธ์ของที่ไหน ๆ ที่เกี่ยวกับ Pattern Recognition ก็บอกคล้าย ๆ กันว่า “ให้ความแม่นยำที่ไม่เกิน 85%” (ขนาด Speech Recognition ที่ผมเคยทำ ยังให้ความแม่นยำได้ที่ 70% เอง แย่กว่าอีก)
แล้วทำไมพวกฝรั่งมันถึงทำได้ถึง 100% ล่ะ? นี่ย่อมแสดงว่าข้อมูลความรู้ที่สอน ๆ กันมา มันมีสิ่งปิดบังอ่ะดิ ผมก็เลยทำใจอ่ะครับว่าข้อมูลความรู้ในโลกนี้มันมี 3 ระดับ คือ ระดับสาธารณะ, ระดับวงจำกัด และระดับลับสุดยอด คนอย่างพวกเราคงเข้าถึงได้แค่สองระดับแรกเท่านั้นเอง
อะไรที่มันเจ๋ง ๆ มักเป็นความลับสุดยอดเสมอเลยเน้อะ? 🙂
[tags]Pattern Recognition, งานวิจัย, Recognition, Fuzzy Logic[/tags]


อัพเกือบทุกวันเลยขยันจริงๆุ นับถือๆ
อ่านบล็อกพี่แล้วผมคิดถึงนิยายวิทยาศาสตร์มาตะหงิดๆ
เคยดูในหนังฝรั่งที่มีคอมพิวเตอร์มาตัดสินการกระทำของมนุษย์
ว่าอันนี้ดี อันนี้ไม่ดี โทษหนัก โทษเบา ฯลฯ
พัฒนาไปเถอะคับผม สนับสนุน แต่อย่าให้ถึงขั้นนั้นเลย – -“
blog ต้อง up ทุกวันถึงจะดีครับ มันจะได้มีชีวิตและรู้สึกว่ามีคนเฝ้า และผมก็นิยมโม้ถึงแต่การพัฒนา software ที่อยู่นอกกรอบชีวิตประจำวันของคนทั่วไปอ่ะครับ
ลองรื้อฟื้นที่เว็บนี้หน่อยมั้ยครับ
Thai Speech Community
ยอดเยี่ยมมาก ๆ ครับมาอ่านที่นี่ได้ความรู้เยอะดีครับ สู้ต่อไปครับ
ผมลองไปอ่านที่ Thai Speech Community ตะกี๊นี้เอง ตามคำแนะนำของคุณ Oakyman พบว่า … 🙂 เขียนเหมือนหนังสือ Fundamental of speech recognition ที่ผมเคยอ่านเลย 🙂 ศาสตร์พวกนี้มันคงจะแนวเดียวกันนะเนี่ย
ขอบคุณครับคุณสิทธิศักดิ์ คุณสิทธิศักดิ์เองก็ up blog บ่อยเหมือนกันนะเนี่ย
Software as a Service มันน่าจะอยู่ในชีวิตประจำวันไม่ใช่เหรอคับผม
ถึงจะกล่าวถึงแค่ผู้พัฒนาแต่ยังไงๆ ก๊อต้องมาถึงชีวิตประจำวันอยู่ดีแหละคับผม -^^-
อุ๊ย …. เคยเรียนเรื่องนี้เหมือนกันครับ ยากมาก ๆ เลย เท่าที่จำได้คล่าว ๆ Prof เคยบอกว่าหากต้องการเพิ่มความถูกต้อง ให้เพิ่ม characteristics (แปลถูกเปล่าหว่า) เข้าไปในระบบ การที่จะหาได้ว่าจะเอาอะไรมาเป็น characteristics มันอาจเป็นศิลป์อย่างนึงครับ ที่พวกฝาหรั่งมันทำได้ดี มันเลยได้ผล 100%
ขึ้นชื่อว่าศิลป์ ผมว่ามันอยู่ที่การฝึกฝนครับ
Fundamental of speech recognition เป็น Bible ของคนที่เีรียนด้านนี้หละครับ
พี่ชัย (คนเขียนเว็บ Thai Speech Community ตอนนี้อยู่เนคเทค)
ก็คงเรียบเรียงมาจากเล่มนั้นแหละครับ
ผมก็อ่าน (บ้าง) แต่อ่านไม่จบ (อ่านไปเจอสมการแล้วมึนตึ้บ)
เลยเน้นใช้ HTK มากกว่าจะหาทฤษฎีใหม่ๆ
เป็นเช่นนั้นแลครับคุณ madz_leng ยังไงมันก็เหวี่ยงมาที่ชีวิตประจำวันอยู่ดี
เห็นด้วยครับคุณโบว์ ไอ้การหา “สิ่งเด่นจำเพาะ” เพื่อยัดเข้าไปในระบบแล้วทำให้มันเป๊ะ ๆ 100% นี่มันศิลป์จริง ๆ ว่าแต่ตกลง computer มันจากศิลป์กลายเป็นวิทย์ แล้วตอนนี้ก็จะย้อนกลับมาเป็นศิลป์อีกแล้วเหรอเนี่ย? ง่ะ
ผมเองก็เหวอไปกับสมการเหมือนกันล่ะคุณ Oakyman สุดท้ายผมเลยเลือกใช้ Linear Predictive Coding Model อ่ะครับ เพราะดูแล้วง่ายสุดแล้ว เฮ้อ ก็คนมันอ่อนคณิตศาสตร์นี่หว่า
ใช้ เครื่องมือ อะไรทำครับ บอกหน่อย matlab หรือ อะไร
เพื่อจะได้ทำบ้าง