
ผมเพิ่งได้มีโอกาสอ่าน แผนพัฒนาเศรษฐกิจ 5 ปี (2021-2025) ฉบับที่ 14 ของจีน (ฉบับแปลจีนเป็นอังกฤษ) ไปเมื่อไม่กี่วันก่อน ถือว่าอ่านช้าไปหน่อย เพราะประกาศมาตั้งแต่เดือนมีนาคมที่ผ่านมา และสื่อมวลชนไทยก็สาธยายรายละเอียดสำคัญไปหมดแล้ว แต่พอได้อ่านเอง ถึงได้รู้ว่าสื่อมวลชนไม่ได้แจกแจงทุกรายละเอียดปลีกย่อย ผมจึงเห็นว่าในเนื้อหามีคำสำคัญหลายคำที่ถูกกล่าวอ้างถึง ล้วนเกี่ยวข้องกับคอมพิวเตอร์ทั้งนั้น ซึ่งได้แก่ คลาวคอมพิวติ้ง บิ๊กดาต้า ไอโอที บล็อกเชน ปัญญาประดิษฐ์ วีอาร์ เออาร์
Category: Data Mining
โม้เกี่ยวกับข้อมูลซึ่งเราจำเป็นต้องไปขุดออกมา เพราะมันไม่ได้เป็นของเรา
เห็นทุกวันนี้งานทางด้าน AI ใช้ Neural Network มากขึ้นเรื่อย ๆ ซึ่งโดยส่วนตัวแล้วไม่ค่อยชอบโมเดลปัญญาประดิษฐ์แบบ Neural Network ซักเท่าไหร่ เพราะ … แปลความยาก คือเวลามันเรียนรู้แล้วสร้างเส้นแบ่ง เส้นแบ่งมันเป็นเส้นโค้ง โค้งไปมาตามข้อมูลที่มันเรียน มันเลยไม่มีความเป็นกลาง ลองนึกถึงว่าเราตีเส้นตรงเพื่อแบ่งเขต เรายังตีความง่าย แต่พอมันโค้ง เราต้องตีความว่าทำไมมันโค้ง มันหลบทำไม มันมีอะไรพิเศษถึงต้องโค้งหลบ (มันเหมือนทางด่วนที่สร้างหลบบ้านคนรวยมั้ย)
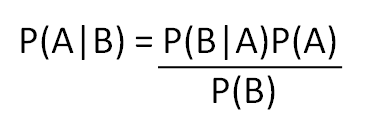
ทฤษฎีบทของเบย์เป็นทฤษฎีความน่าจะเป็นเชิงอนุมานที่ถูกใช้กันอย่างกว้างขวางในงานคอมพิวเตอร์ชั้นสูงครับ ไม่ว่าจะเป็นการรู้จำแบบมีผู้สอนเชิงเส้นด้วย Naive Bayes หรือ การรู้จำเสียงพูดด้วย Hidden Markov Model หรือ การคำนวณสภาวะ Superposition ของคิวบิตในควอนตัมคอมพิวเตอร์ ก็ล้วนตั้งอยู่บนหลักการของทฤษฎีบทของเบย์ทั้งนั้น โดยหน้าตาของสมการตามทฤษฎีบทของเบย์ก็เป็นแบบข้างล่างนี้ จริง ๆ แล้วทฤษฎีบทของเบย์ก็สืบต่อมาจากทฤษฎีความน่าจะเป็นแบบมีเงื่อนไขอีกทีนึงน่ะครับ เป็นโมเดลที่อธิบายว่าความน่าจะเป็นในลำดับถัดไปจะขึ้นกับความน่าจะเป็นของลำดับก่อนหน้า อะไรประมาณนั้น ซึ่งถ้าจะคำนวณความน่าจะเป็นของลำดับถัดไปโดยขึ้นกับความน่าจะเป็นของลำดับก่อนหน้า ก็สามารถทำได้ง่าย ๆ ตามสมการข้างล่างนี้ครับ แล้วในเมื่อมันมีสมการง่าย
คืองี้ครับ ในวิชา Data Mining หรือ Machine Learning มันจะมีอยู่ปัญหานึงที่มักถูกหยิบยกขึ้นมานำเสนออยู่เสมอ นั่นคือ ปัญหาการจำแนกผลลัพธ์โดยการพิจารณาจากคุณสมบัติของข้อมูลที่ฝึกฝน เช่น ใช้ส่วนสูง หรือ น้ำหนัก ประกอบกัน เพื่อจะจำแนกว่าบุคคลคนนั้น เป็นนักบาสเก็ตบอลหรือนักซูโม่หรือนักมวย ซึ่งถ้าในทางทฤษฎีเราสามารถจำแนกว่า นักบาสเก็ตบอลคือ Class ที่หนึ่งส่วนนักซูโม่ก็เป็น Class ที่สอง และนักมวยก็เป็น Class
ทุกวันนี้คอมพิวเตอร์มันยังคิดเองไม่ได้นะครับ ขอบอกไว้ก่อนตรงนี้เลยว่ามันยังคิดเองไม่ได้ สิ่งที่มันทำได้คือการเรียนรู้จากข้อมูลที่ถูกเฉลยเอาไว้ก่อนแล้ว จากนั้นเมื่อมีข้อมูลใหม่ถูกป้อนเข้ามาเพื่อขอคำตอบ มันก็จะนำเอาสิ่งที่มันเคยเรียนรู้ซึ่งเคยถูกเฉลยเอาไว้ มาทบทวนเพื่อทำนายว่าข้อมูลใหม่ควรจะเฉลยคำตอบว่ายังไง และคำตอบควรจะเป็นยังไง โดยผู้ที่เฉลยคำตอบให้กับคอมพิวเตอร์ในขั้นตอนการเรียนรู้ ก็คือมนุษย์เราเนี่ยแหล่ะ!!! ยกตัวอย่างเช่น เราอยากให้คอมพิวเตอร์แยกแยะได้ระหว่าง ส้ม กับ แอปเปิ้ล เราก็จะเอาข้อมูลคุณสมบัติของส้มซัก 20 ลูก พร้อมทั้งเฉลยว่าคุณสมบัติเหล่านั้นคือส้ม และเอาข้อมูลคุณสมบัติของแอปเปิ้ลซัก 20 ลูก พร้อมทั้งเฉลยว่าคุณสมบัติเหล่านั้นคือแอปเปิ้ล ป้อนเข้าไปให้คอมพิวเตอร์มันเรียนรู้ มันก็จะพยายามทบทวนของมันไป จนมันได้อะไรซักอย่างนึงออกมาเพื่อจะบอกว่ามันเรียนรู้ได้ล่ะ
ผมเชื่อมาตลอดว่างานวิจัยทางด้าน Predict ง่ายกว่าทางด้าน Mining เพราะงานวิจัยทาง Predict ส่วนใหญ่แล้วพิสูจน์ได้ด้วยการหา ROC curve จะมีส่วนน้อยเท่านั้นที่ต้องใช้ Domain Expert เข้ามาช่วย เช่น งานทางด้าน Facial Recognition เป็นต้น ในขณะที่งานวิจัยทางด้าน Mining ส่วนใหญ่แล้วต้องพิสูจน์ด้วย Domain Expert เพราะการหาความรู้จากข้อมูล มันไม่สามารถพิสูจน์ได้ถ้าไม่มีผู้เชี่ยวชาญมาตัดสินว่าถูกหรือผิด
อาจารย์ผมเคยสอนว่า ถ้าเราจะทำวิจัยเรื่องอะไร เราก็ต้องดูก่อนว่าตอนนี้โลกเขาไปถึงไหนกันแล้ว และผมก็เชื่อเหลือเกินว่าตอนนี้พวกเราก็คงจะรู้แล้วว่าโลกอินเทอร์เน็ตนั้นสำคัญและมีพลังมากขนาดไหน!! หลายปีที่ผ่านมา ประชาคมอินเทอร์เน็ตได้ช่วยกันสร้างเนื้อหาต่าง ๆ และโอนมันขึ้นไปอยู่บนระบบอินเทอร์เน็ตมากมายมหาศาล ไม่ว่าสิ่งนั้นจะเป็น ข้อความ ภาพ เสียง วีดีโอ แฟ้มไบนารี่ ซึ่งการกระทำเหล่านั้นล้วนผ่านทั้งกระบวนการของ User Generated Content และหรือ Human Based Computation เนื้อหาที่มากมายมหาศาลที่ถูกสร้างขึ้นเหล่านั้น เป็นก้อนข้อมูลขนาดมหึมาซึ่งต้องมีพื้นที่จัดเก็บที่มีขนาดทัดเทียมกันหรือมากกว่ารองรับ ทุกอย่างมันต้องสอดคล้องกัน เพราะจำนวนคนในประชาคมอินเทอร์เน็ตที่สร้างเนื้อหามีจำนวนมากมายเป็นล้าน ๆ คน ในขณะที่พื้นที่จัดเก็บก็ต้องขยายตามไปด้วย
เอาใจความหลักๆก่อนแล้วกัน Machine Learning คือ การให้คอมพิวเตอร์ทำนายผลลัพธ์ โดยใช้ข้อมูลพื้นฐานจาก attribute ที่รู้จักมาก่อนจากขั้นตอนการ train Data Mining คือ การค้นพบความรู้จากข้อมูล โดยข้อมูลที่ใช้เพื่อการค้นพบนั้นเป็น attribute ที่ไม่เคยรู้จักมาก่อน ดังนั้น ความแตกต่างของทั้งสองอย่างอยู่ที่กริยาของพวกมัน เพราะอย่างนึงคิดค้นขึ้นเพื่อการ “ทำนาย” ส่วนอีกตัวนึงคิดค้นขึ้นเพื่อการ “ค้นพบ” ส่วนสิ่งที่เหมือนกันของทั้งสองอย่างคือ “ข้อมูล” เพราะในแง่ของ
ผมได้รับการบ้านมาครับ เป็นการบ้านระยะยาว รายละเอียดของการบ้านก็คือ ต้องทำ Demo ของ Paper งานวิจัยขึ้นมาซักเรื่องนึงที่เกี่ยวกับหัวข้อที่เรียนมา ผมจึงเลือกที่จะลองทำการวิเคราะห์ความสัมพันธ์ของหุ้นด้วย Association Rule Mining ดู ผมทำไปแล้วและส่งไปแล้ว และมันเป็น Demo ของ Paper ที่ไม่สามารถนำไปต่อยอดเพื่อตีพิมพ์หรือประชุมวิชาการได้อย่างแน่นอน เพราะมันมีจุดบกพร่องอยู่ 3 ข้อใหญ่ ๆ โดยจุดบกพร่องข้อแรกก็คือ ผมไม่ได้คิดอะไรใหม่เลย ผมแค่เอาสิ่งที่มีอยู่แล้วมาประกอบกันเพื่อสร้างเป็นผลลัพธ์ จุดบกพร่องข้อสองคือ
ความรู้ทางคอมพิวเตอร์มีอยู่สองรูปแบบ คือ ความรู้เพื่อแสดงภูมิปัญญา และ ความรู้เพื่อการเอาตัวรอด!!! ว่ากันตามจริงแล้ว บล็อกแห่งนี้ก็โม้แต่ความรู้ทางคอมพิวเตอร์ ในรูปแบบความรู้เพื่อแสดงภูมิปัญญา โดยมีความรู้ทั่วไปนิด ๆ หน่อย ๆ และเน้นความรู้ชั้นสูงมากหน่อย!!! แต่โดยส่วนตัวแล้ว ผมยกย่องคนที่มีความรู้ทางคอมพิวเตอร์เพื่อการเอาตัวรอดนะ 😛 ยิ่งคนเหล่านั้นมีความรู้ทางคอมพิวเตอร์เพื่อการเอาตัวรอดแบบชั้นสูงมากเท่าไหร่ ก็ยิ่งน่ายกย่องมากขึ้นเท่านั้น … แต่เหนือสิ่งอื่นใด การสกัดเอาความรู้ทางคอมพิวเตอร์ในรูปแบบความรู้เพื่อการเอาตัวรอด (ชั้นสูง) เป็นเรื่องที่ไม่ง่ายนัก เปรียบได้กับการสกัดเอาทองคำออกจากหินแร่ต่าง ๆ