
ผมเพิ่งได้มีโอกาสอ่าน แผน
หมวดหมู่: Data Mining
โม้เกี่ยวกับข้อมูลซึ่งเราจำเป็นต้องไปขุดออกมา เพราะมันไม่ได้เป็นของเรา
เห็นทุกวันนี้งานทางด้าน A
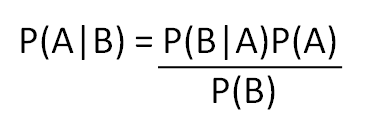
ทฤษฎีบทของเบย์เป็นทฤษฎีคว
คืองี้ครับ ในวิชา Data Mi
ทุกวันนี้คอมพิวเตอร์มันยั
ผมเชื่อมาตลอดว่างานวิจัยท
อาจารย์ผมเคยสอนว่า ถ้าเรา
เอาใจความหลักๆก่อนแล้วกัน
ผมได้รับการบ้านมาครับ เป็
ความรู้ทางคอมพิวเตอร์มีอย