พวกเราคงจำข่าวที่ Google ทดสอบประสิทธิภาพของควอนตัมคอมพิวเตอร์ยี่ห้อ D-Wave X2 แล้วได้ผลว่ามันทำงานได้เร็วกว่าดิจิทัลคอมพิวเตอร์ทั่วไปเป็น 100 ล้านเท่ากันได้ และผมก็คิดว่าพวกเราคงรู้กันแล้วล่ะ ว่าเบื้องหลังความเร็วของควอนตัมคอมพิวเตอร์ เกิดจากการประยุกต์ใช้สภาวะ Superposition ของคิวบิต ทีนี้ ผมเลยอยากจะช่วยขยายความเพิ่มลงในระดับของทฤษฎีความซับซ้อนในการคำนวณนิดนึง เพื่อให้พวกเราเห็นภาพมากขึ้นว่าทำไมควอนตัมคอมพิวเตอร์จึงเร็ว โดยพื้นฐานแล้ว (ในทางวิทยาการคอมพิวเตอร์เขาบอกไว้) หากปัญหามีขนาดใหญ่มากกว่าค่าหนึ่ง เพื่อให้ได้ประสิทธิภาพ ดิจิทัลคอมพิวเตอร์จะต้องวนรอบหรือเรียกตัวเองซ้ำ เพื่อคำนวณให้ได้คำตอบของปัญหา ยิ่งปัญหามีขนาดใหญ่มาก และมีความซับซ้อนมาก ก็ยิ่งต้องวนรอบซ้อนกันหลายชั้นมากขึ้น
Author: ไท้ ปริญญา
เข้าใจว่าตอนนี้หลาย ๆ คนในวงการคอมพิวเตอร์คงจะรู้จักควอนตัมคอมพิวเตอร์กันแล้ว ซึ่งคนที่รู้จักก็น่าจะแบ่งได้เป็น 3 กลุ่มใหญ่ ๆ 1. กลุ่มรู้ทั่วไป คือ กลุ่มที่ตามข่าวของควอนตัมคอมพิวเตอร์ จึงรู้จักคิวบิตและสภาวะ Superposition ของมัน รู้จักความพัวพันเชิงควอนตัม รู้จักการประมวลผลขนานแบบควอนตัม และรู้จักควอนตัมคอมพิวเตอร์ยี่ห้อต่าง ๆ ที่ถูกผลิตโดยบริษัทชั้นนำของโลก 2. กลุ่มรู้เยอะ คือ กลุ่มที่อ่านเปเปอร์ด้านควอนตัมคอมพิวเตอร์มาแล้วหลายฉบับ มีความรู้ในการคำนวณสภาวะ Superposition

ผมเคยเขียนเรื่องหลักสูตรคอมพิวเตอร์ในเมืองไทยเอาไว้ จุดประสงค์เพื่อเรียบเรียงว่าตอนนี้มหาวิทยาลัยในเมืองไทย เปิดหลักสูตรที่เกี่ยวข้องกับคอมพิวเตอร์ในระดับปริญญาและบัณฑิตศึกษากี่หลักสูตรบ้าง ตอนนี้ผมเลยคิดว่าผมต้องมาปรับปรุงมันใหม่อีกครั้ง เพราะโลกมันเปลี่ยน มันมีวิทยาการใหม่ ๆ เกิดขึ้นมา หลักสูตรทางคอมพิวเตอร์มันก็เปลี่ยนตาม แถมคราวที่แล้วผมก็ไม่ได้อธิบายไว้อย่างชัดเจนมากนัก ว่าแต่ล่ะหลักสูตรเขามีจุดประสงค์ในการเปิดการเรียนการสอนเพื่ออะไรบ้าง ในหัวข้อนี้เลยจะมาเล่าให้อ่านกันสั้น ๆ ผมสรุปแล้ว (สรุปเอง) ว่าเราสามารถจัดหลักสูตรคอมพิวเตอร์ในเมืองไทยได้ 10 หลักสูตรใน 4 วุฒิการศึกษาครับ ตามรายการด้านล่างนี้ วุฒิวิทยาศาสตร์ วิทยาการคอมพิวเตอร์ (Computer Science)

ก่อนที่เราจะเข้าเรื่องกัน ผมอยากจะค่อย ๆ เล่าให้เห็นภาพว่า มนุษย์เราเหนือกว่าสัตว์ได้ยังไง แล้วมนุษย์เราเหนือกว่ามนุษย์ด้วยกันเองได้ยังไง และอะไรที่ทำให้เผ่าพันธุ์หนึ่งเหนือกว่าอีกเผ่าพันธุ์หนึ่ง และอารยธรรมหนึ่งเหนือกว่าอีกอารยธรรมหนึ่ง มนุษย์เราจริง ๆ แล้วอ่อนแอ ถ้าเราแก้ผ้ามือเปล่าสู้กับหมีเราคอหักตายแน่ หรือถ้าเราไม่สู้หมีแต่ไปสู้เสือล่ะ ผลก็ไม่แตกต่าง เพียงแต่เปลี่ยนเป็นหน้าแหกเพราะกรงเล็บและคอถูกขย้ำด้วยเขี้ยวแทน มนุษย์เราก็เหมือนกับสัตว์หรือแม้แต่แมลง เราต้องดิ้นรนเพื่อเอาตัวรอด เราต้องการอาหาร เครื่องนุ่งห่ม ที่อยู่อาศัย ยารักษาโรค เพื่อหล่อเลี้ยงให้เราดำรงชีพอยู่ จากนั้นเราก็ต้องการความปลอดภัย สิ่งเหล่านี้ล้วนเป็นไปตามลำดับความต้องการแบบปัจเจกบุคคลที่เสนอโดยมาสโลว์เป๊ะ การให้ได้มาซึ่งปัจจัยเหล่านี้
เราจะเห็นว่าทุกวันนี้เครื่องจักรที่คิดหรือตัดสินใจอะไรเองได้ เริ่มเข้ามามีบทบาทในชีวิตประจำวันเรามากขึ้นเรื่อย ๆ และการที่มันทำพฤติกรรมแบบนี้ได้ เราก็มักจะมีคำจำกัดความให้มัน เรามักจะเรียกมันว่า “ปัญญาประดิษฐ์” บ้าง หรือไม่ก็เรียกว่า “ระบบอัจฉริยะ” บ้าง อะไรประมาณนั้น จริง ๆ แล้วเบื้องหลังของการที่มันคิดหรือตัดสินใจได้ เกิดจากปัจจัยเพียง 2 สิ่งเท่านั้น นั่นก็คือ “การคำนวณ” และ “ข้อมูล” จุดประสงค์ของการคำนวณโดยใช้ข้อมูลประกอบ ก็เพื่อหาคำตอบที่ดีที่สุด สำหรับสังเคราะห์
ทุกวันนี้คอมพิวเตอร์มันเก่งมากในการประมวลผลซอฟต์แวร์ แต่มันยังไม่ถึงจุดที่มันจะสร้างซอฟต์แวร์เองได้ ดังนั้น มนุษย์เลยยังคงต้องรับผิดชอบเป็นผู้สร้างซอฟต์แวร์อยู่ ในงานสร้างซอฟต์แวร์โดยเฉพาะซอฟต์แวร์ขนาดใหญ่ มักจะต้องแบ่งงานกันทำ เพราะทำคนเดียวไม่ได้ มันเสร็จช้า และก็อาจจะไม่ประณีตในหลาย ๆ เรื่อง ดังนั้น แบ่งกันทำดีกว่า ปรกติแล้วการสร้างซอฟต์แวร์ถ้ามีคนพอ จะแบ่งงานออกเป็น 3 ส่วนใหญ่ ๆ คืองาน Management งาน Functional และงาน Technical ทีนี้เรามาสมมติว่าเราเป็นผู้อำนวยการสร้างกันดีกว่า
หลายวันก่อนอ่านในกระทู้พันทิป เหมือนมีคนมาตั้งกระทู้ถามว่า กระบวนการแปลภาษาทางคอมพิวเตอร์มันเป็นยังไง แบบว่าไม่เข้าใจ อะไรประมาณนั้น ซึ่งผมมองว่าเป็นคำถามที่ดี เพราะแสดงว่าเขากำลังสนใจวัตถุประสงค์ของการแปลภาษาทางคอมพิวเตอร์ มากกว่าสนใจในภาษาคอมพิวเตอร์ชั้นสูง ซึ่งมีออกมาใหม่ ๆ กันมากมายหลายภาษาซะเหลือเกิน ผมคิดว่าคนที่ตั้งกระทู้ถาม น่าจะเป็นคนรุ่นใหม่ ผมเองเห็นใจคนรุ่นใหม่มาก เพราะพวกเขาอยู่ในยุคสมัยที่ช่องว่างระหว่างเทคโนโลยีต้นน้ำกับเทคโนโลยีปลายน้ำมันห่างออกไปทุกที พวกเขากำลังถูกผลักให้กลายเป็นผู้ใช้งาน มากกว่าเป็นผู้คิดค้นวิจัยพัฒนา พวกเขาถูกสิ่งกีดกันที่เรียกว่าเวลาในการเรียนรู้มาขวางทางเขาเอาไว้ พวกเขาต้องมีเวลามากพอในการเรียนรู้ย้อนกลับจากเทคโนโลยีปลายน้ำไปหาเทคโนโลยีต้นน้ำ เพื่อทำความเข้าใจที่มาที่ไป เพื่อจะได้สร้างเทคโนโลยีปลายน้ำใหม่ ๆ หรือตั้งต้นสร้างเทคโนโลยีต้นน้ำใหม่ได้ เมืองไทยเรานับคนได้เลย ที่คิดจะคิดภาษาคอมพิวเตอร์ชั้นสูง
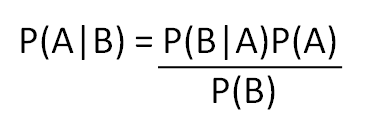
ทฤษฎีบทของเบย์เป็นทฤษฎีความน่าจะเป็นเชิงอนุมานที่ถูกใช้กันอย่างกว้างขวางในงานคอมพิวเตอร์ชั้นสูงครับ ไม่ว่าจะเป็นการรู้จำแบบมีผู้สอนเชิงเส้นด้วย Naive Bayes หรือ การรู้จำเสียงพูดด้วย Hidden Markov Model หรือ การคำนวณสภาวะ Superposition ของคิวบิตในควอนตัมคอมพิวเตอร์ ก็ล้วนตั้งอยู่บนหลักการของทฤษฎีบทของเบย์ทั้งนั้น โดยหน้าตาของสมการตามทฤษฎีบทของเบย์ก็เป็นแบบข้างล่างนี้ จริง ๆ แล้วทฤษฎีบทของเบย์ก็สืบต่อมาจากทฤษฎีความน่าจะเป็นแบบมีเงื่อนไขอีกทีนึงน่ะครับ เป็นโมเดลที่อธิบายว่าความน่าจะเป็นในลำดับถัดไปจะขึ้นกับความน่าจะเป็นของลำดับก่อนหน้า อะไรประมาณนั้น ซึ่งถ้าจะคำนวณความน่าจะเป็นของลำดับถัดไปโดยขึ้นกับความน่าจะเป็นของลำดับก่อนหน้า ก็สามารถทำได้ง่าย ๆ ตามสมการข้างล่างนี้ครับ แล้วในเมื่อมันมีสมการง่าย
เวลาเรียนคอมพิวเตอร์เราก็ต้องเรียนอะไรที่ยาก ๆ ถูกมั้ยครับ แต่ชีวิตจริงออกไปทำงาน ไอ้ที่ยาก ๆ ที่เรียนไปมักไม่ค่อยได้ใช้ เพราะงานส่วนใหญ่ในชีวิตจริงเป็นงานเชิงธุรกิจ เป็นเรื่องเกี่ยวกับการรับจ้างทำงาน การค้าขาย ดังนั้น เรื่องเงิน ๆ ทอง ๆ เลยกลายเป็นเรื่องหลัก การดูแลเงินทองข้าวของและการดูแลลูกค้าก็เลยเป็นปัจจัยสำคัญในการทำธุรกิจไป ดังนั้น ระบบคอมพิวเตอร์จึงมักถูกติดตั้งและพัฒนาเพื่อการดูแลเงินทองและดูแลลูกค้าตามที่กล่าวมา ระบบคอมพิวเตอร์ที่เอาไว้ดูแลเงินทองข้าวของ ในภาพใหญ่สุดจะเรียกว่า Enterprise Resource Planning ส่วนภาพที่เล็กลงมาก็แบ่งได้เป็น
คืองี้ครับ ในวิชา Data Mining หรือ Machine Learning มันจะมีอยู่ปัญหานึงที่มักถูกหยิบยกขึ้นมานำเสนออยู่เสมอ นั่นคือ ปัญหาการจำแนกผลลัพธ์โดยการพิจารณาจากคุณสมบัติของข้อมูลที่ฝึกฝน เช่น ใช้ส่วนสูง หรือ น้ำหนัก ประกอบกัน เพื่อจะจำแนกว่าบุคคลคนนั้น เป็นนักบาสเก็ตบอลหรือนักซูโม่หรือนักมวย ซึ่งถ้าในทางทฤษฎีเราสามารถจำแนกว่า นักบาสเก็ตบอลคือ Class ที่หนึ่งส่วนนักซูโม่ก็เป็น Class ที่สอง และนักมวยก็เป็น Class