ตอนนี้ Deep Learning เป็นพระเอกของปัญญาประดิษฐ์ ผมเลยคิดว่าจะชวนพวกเราคุยเรื่องที่ไม่ค่อยมีคนคุย นั่นก็คือ Big O ในการคำนวณ Deep Learning น่าจะอยู่ในคลาสไหน? จริง ๆ แล้ว ไม่ว่าจะเป็น Perceptron หรือ Multi-layer Perceptron หรือ Deep Learning ผมก็วิเคราะห์ว่า Big
Category: Artificial Intelligence
โม้เกี่ยวกับเทคโนโลยี Artificial Intelligence

ผมอยากลองใช้ Tensorflow ตามกระแสครับ คือจริง ๆ มันก็มีเครื่องมือหลายตัวที่ทำงานด้าน AI ได้ ไม่ว่าจะเป็น Matlab, Octave, Weka หรือ RapidMiner (รวมทั้ง Library หรือ Framework ด้าน AI ที่ใช้กับภาษา C/C++) แต่ว่าเครื่องมือเหล่านั้นเป็นสหสาขา AI เลยทำได้แบบกลาง
เห็นทุกวันนี้งานทางด้าน AI ใช้ Neural Network มากขึ้นเรื่อย ๆ ซึ่งโดยส่วนตัวแล้วไม่ค่อยชอบโมเดลปัญญาประดิษฐ์แบบ Neural Network ซักเท่าไหร่ เพราะ … แปลความยาก คือเวลามันเรียนรู้แล้วสร้างเส้นแบ่ง เส้นแบ่งมันเป็นเส้นโค้ง โค้งไปมาตามข้อมูลที่มันเรียน มันเลยไม่มีความเป็นกลาง ลองนึกถึงว่าเราตีเส้นตรงเพื่อแบ่งเขต เรายังตีความง่าย แต่พอมันโค้ง เราต้องตีความว่าทำไมมันโค้ง มันหลบทำไม มันมีอะไรพิเศษถึงต้องโค้งหลบ (มันเหมือนทางด่วนที่สร้างหลบบ้านคนรวยมั้ย)
เดี๋ยวนี้ ผลิตภัณฑ์อิเล็กทรอนิกส์ที่บรรจุคุณสมบัติของ AI หรือ ปัญญาประดิษฐ์ มีมากขึ้นเรื่อยๆ ปัญญาประดิษฐ์มีหลายแขนงมาก จะอธิบายให้เข้าใจง่ายๆ ก็ไม่ใช่เรื่องง่ายๆ แต่ก็จะลองอธิบายดู 1. Machine Learning คือ การให้เครื่องมันเรียนรู้ข้อมูลที่รู้จักมาก่อน และมีผลเฉลยอยู่ก่อนแล้ว โดยมนุษย์เรานั่นแหล่ะเฉลยเอาไว้ ให้มันเรียนเข้าไป เรียนเยอะๆ จุดประสงค์ก็เพื่อว่า ถ้ามีข้อมูลใหม่เข้ามา ก็จะได้ให้มันทำนายด้วยตัวเอง ว่าด้วยข้อมูลแบบนี้นะ ผลเฉลยมันควรจะเป็นยังไง จากนั้นพอมันเก่งมากพอ

ก่อนที่เราจะเข้าเรื่องกัน ผมอยากจะค่อย ๆ เล่าให้เห็นภาพว่า มนุษย์เราเหนือกว่าสัตว์ได้ยังไง แล้วมนุษย์เราเหนือกว่ามนุษย์ด้วยกันเองได้ยังไง และอะไรที่ทำให้เผ่าพันธุ์หนึ่งเหนือกว่าอีกเผ่าพันธุ์หนึ่ง และอารยธรรมหนึ่งเหนือกว่าอีกอารยธรรมหนึ่ง มนุษย์เราจริง ๆ แล้วอ่อนแอ ถ้าเราแก้ผ้ามือเปล่าสู้กับหมีเราคอหักตายแน่ หรือถ้าเราไม่สู้หมีแต่ไปสู้เสือล่ะ ผลก็ไม่แตกต่าง เพียงแต่เปลี่ยนเป็นหน้าแหกเพราะกรงเล็บและคอถูกขย้ำด้วยเขี้ยวแทน มนุษย์เราก็เหมือนกับสัตว์หรือแม้แต่แมลง เราต้องดิ้นรนเพื่อเอาตัวรอด เราต้องการอาหาร เครื่องนุ่งห่ม ที่อยู่อาศัย ยารักษาโรค เพื่อหล่อเลี้ยงให้เราดำรงชีพอยู่ จากนั้นเราก็ต้องการความปลอดภัย สิ่งเหล่านี้ล้วนเป็นไปตามลำดับความต้องการแบบปัจเจกบุคคลที่เสนอโดยมาสโลว์เป๊ะ การให้ได้มาซึ่งปัจจัยเหล่านี้
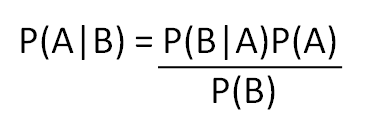
ทฤษฎีบทของเบย์เป็นทฤษฎีความน่าจะเป็นเชิงอนุมานที่ถูกใช้กันอย่างกว้างขวางในงานคอมพิวเตอร์ชั้นสูงครับ ไม่ว่าจะเป็นการรู้จำแบบมีผู้สอนเชิงเส้นด้วย Naive Bayes หรือ การรู้จำเสียงพูดด้วย Hidden Markov Model หรือ การคำนวณสภาวะ Superposition ของคิวบิตในควอนตัมคอมพิวเตอร์ ก็ล้วนตั้งอยู่บนหลักการของทฤษฎีบทของเบย์ทั้งนั้น โดยหน้าตาของสมการตามทฤษฎีบทของเบย์ก็เป็นแบบข้างล่างนี้ จริง ๆ แล้วทฤษฎีบทของเบย์ก็สืบต่อมาจากทฤษฎีความน่าจะเป็นแบบมีเงื่อนไขอีกทีนึงน่ะครับ เป็นโมเดลที่อธิบายว่าความน่าจะเป็นในลำดับถัดไปจะขึ้นกับความน่าจะเป็นของลำดับก่อนหน้า อะไรประมาณนั้น ซึ่งถ้าจะคำนวณความน่าจะเป็นของลำดับถัดไปโดยขึ้นกับความน่าจะเป็นของลำดับก่อนหน้า ก็สามารถทำได้ง่าย ๆ ตามสมการข้างล่างนี้ครับ แล้วในเมื่อมันมีสมการง่าย
คืองี้ครับ ในวิชา Data Mining หรือ Machine Learning มันจะมีอยู่ปัญหานึงที่มักถูกหยิบยกขึ้นมานำเสนออยู่เสมอ นั่นคือ ปัญหาการจำแนกผลลัพธ์โดยการพิจารณาจากคุณสมบัติของข้อมูลที่ฝึกฝน เช่น ใช้ส่วนสูง หรือ น้ำหนัก ประกอบกัน เพื่อจะจำแนกว่าบุคคลคนนั้น เป็นนักบาสเก็ตบอลหรือนักซูโม่หรือนักมวย ซึ่งถ้าในทางทฤษฎีเราสามารถจำแนกว่า นักบาสเก็ตบอลคือ Class ที่หนึ่งส่วนนักซูโม่ก็เป็น Class ที่สอง และนักมวยก็เป็น Class
ทุกวันนี้คอมพิวเตอร์มันยังคิดเองไม่ได้นะครับ ขอบอกไว้ก่อนตรงนี้เลยว่ามันยังคิดเองไม่ได้ สิ่งที่มันทำได้คือการเรียนรู้จากข้อมูลที่ถูกเฉลยเอาไว้ก่อนแล้ว จากนั้นเมื่อมีข้อมูลใหม่ถูกป้อนเข้ามาเพื่อขอคำตอบ มันก็จะนำเอาสิ่งที่มันเคยเรียนรู้ซึ่งเคยถูกเฉลยเอาไว้ มาทบทวนเพื่อทำนายว่าข้อมูลใหม่ควรจะเฉลยคำตอบว่ายังไง และคำตอบควรจะเป็นยังไง โดยผู้ที่เฉลยคำตอบให้กับคอมพิวเตอร์ในขั้นตอนการเรียนรู้ ก็คือมนุษย์เราเนี่ยแหล่ะ!!! ยกตัวอย่างเช่น เราอยากให้คอมพิวเตอร์แยกแยะได้ระหว่าง ส้ม กับ แอปเปิ้ล เราก็จะเอาข้อมูลคุณสมบัติของส้มซัก 20 ลูก พร้อมทั้งเฉลยว่าคุณสมบัติเหล่านั้นคือส้ม และเอาข้อมูลคุณสมบัติของแอปเปิ้ลซัก 20 ลูก พร้อมทั้งเฉลยว่าคุณสมบัติเหล่านั้นคือแอปเปิ้ล ป้อนเข้าไปให้คอมพิวเตอร์มันเรียนรู้ มันก็จะพยายามทบทวนของมันไป จนมันได้อะไรซักอย่างนึงออกมาเพื่อจะบอกว่ามันเรียนรู้ได้ล่ะ
การวิเคราะห์ภาพสมองเป็นหนึ่งในงานวิจัยที่กำลังเป็นที่นิยมในชาติมหาอำนาจในขณะนี้ครับ เพราะสมองเป็นสิ่งที่ทำให้มนุษย์มีความเหนือกว่าสัตว์และพืชทั้งปวงในสากลโลกนี้ ดังนั้น หากมีความเข้าอกเข้าใจในสมองได้ ซึ่งไม่จำเป็นต้องเข้าใจตรง ๆ ก็ได้ เข้าใจอ้อม ๆ ก็ได้ ก็จะทำให้เราสามารถที่จะอ่านจิตใจของเจ้าของสมองได้ และสามารถทำนายพฤติกรรมของเจ้าของสมองได้ (รู้สึกจะพิมพ์ “ได้” หลายตัวแฮะ) ทุกวันนี้มีเทคโนโลยีในการถ่ายภาพสมองอยู่หลายแบบครับ ซึ่งทั้งหมดล้วนใช้คลื่นแม่เหล็กไฟฟ้าความเข้มสูงในการถ่ายภาพ โดยหลักการคือการปล่อยให้คลื่นแม่เหล็กไฟฟ้าผ่านปริมาตรสมอง แล้วตรวจสอบการดูดกลืนหรือสะท้อนกลับของคลื่นแม่เหล็กไฟฟ้า เพื่อแสดงออกมาเป็นภาพสามมิติ แล้วตรวจวิเคราะห์บริเวณที่มีการตอบสนองเป็นพิเศษ ซึ่งการตอบสนองอาจจะอยู่ในรูปของบริเวณที่มีความแตกต่างเชิงพื้นที่หรือเชิงเวลา คือแบบว่าตรงไหนมันดูเด่นกว่าใคร ๆ ก็ตรงนั้นแหล่ะเป็นลักษณะพิเศษ
ถ้าเราเปรียบสิ่งมีชีวิตเป็นสิ่งที่แสนวิเศษ งั้นเราก็คงต้องถือว่าข้อมูล Bioinformatics ของสิ่งมีชีวิตเป็นสิ่งที่แสนวิเศษยิ่งกว่า!!! ปัจจุบันงานวิจัยทาง Bioinformatics กำลังก้าวหน้าไปเรื่อย ๆ ครับ ทิ้งให้คนรุ่นหลังต้องวิ่งไล่กวดศึกษาให้ทัน ดังนั้น แค่เรียนให้ทันความคิดของคนรุ่นก่อนได้ก็หืดขึ้นคอแล้ว ซึ่งงานทางด้าน Bioinformatics ก็มีหลายอย่างครับ สากกะเบือยันเรือรบ แต่ส่วนใหญ่ก็ยุ่งอยู่กับข้อมูลปริมาณอภิมหามหึมาของลักษณะทางพันธุกรรมของสิ่งมีชีวิตอะไรประมาณนั้น ผมเองก็ได้การบ้านมาทำเรื่องนี้เหมือนกัน เป็นงานร่างเปเปอร์เพื่อลองผิดลองถูกในการคัดเลือกลักษณะเฉพาะทางพันธุกรรมของสิ่งมีชีวิต เพื่อนำมาเข้าสู่กระบวนการเครื่องจักรเรียนรู้ สอนให้เครื่องจักรมันรู้วิธีแยกแยะลักษณะปรากฎของสิ่งมีชีวิต โดยใช้ลักษณะทางพันธุกรรมของตัวมันเองนั่นแหล่ะเป็นตัวแยกแยะ ก็ยังคงเหมือนเดิมครับ เปเปอร์นี้ของผมไม่ได้มีการคิดอะไรใหม่ เป็นแค่การเรียบเรียงสิ่งที่น่าจะพอใช้ได้เอามารวม